서론
지난 두 편의 글에서는 마이그레이션 사전작업으로 CI 시간 최적화를 다뤘습니다. 마이그레이션 대상 서버는 2013년부터 개발되어 최근까지 Python 2.7로 운영되고 있었는데, 해당 버전은 2020년 1월에 공식 지원이 중단되어 보안 패치가 더 이상 제공되지 않는 상태였습니다. 향후 사내 인프라를 Graviton 프로세서 기반으로 전환하기 위해서라도 Python 3로의 버전 업그레이드가 필요했습니다.
이번 포스트에서는 본격적인 마이그레이션 과정을 공유합니다. 단순히 python2 문법을 수정하는 것과 더불어 패키지 관리 도구를 pip-tools에서 uv로, 린터를 flake8에서 ruff로 교체하는 등 도구 전반을 현대화하는 작업을 함께 진행했습니다.
사전 작업: 로그 구조화 - plain text에서 구조화 JSON으로
본격적인 작업 전에 마이그레이션 진행 시 발생할 예상 외의 에러에 대응하기 위한 로그 구조화가 필요했습니다. 기존 서비스의 로그는 Django 기본 설정인 plain text 형태 였기 때문에 원하는 정보를 한 눈에 파악하기 어려웠습니다. 아래와 같이 timestamp, level, message 가 한 줄로 출력되고 있어 로그 검색이나 필터링에는 불편했습니다. 사내 로그 검색 인프라인 loki, grafana 에서 로그를 확인할 때도 plain text 로 출력되는 로그는 에러 메시지와 트레이스백이 여러 줄에 걸쳐 출력돼 식별이 어려웠기 때문에 json 으로 structured log 형태로 변경하는 작업을 선행했습니다.
bash// before [2025-01-15 14:23:45] ERROR django.request: Internal Server Error: /user/login/ Traceback (most recent call last): File "/honeyscreen/billi/decorators.py", line 243, in authorize_login ...
위처럼 에러 메시지와 트레이스백이 여러 줄에 걸쳐 출력되면 Loki 같은 로그 수집 도구에서 하나의 에러 이벤트를 식별하기가 어렵습니다. level 기준 필터링이나 특정 필드 기반 검색도 정규표현식에 의존해야 해서 에러 조사에 시간이 많이 소요됐습니다.
JSON 구조화 로그
이 문제를 해결하기 위해 로그 출력을 JSON 형태로 구조화했습니다. 변경의 핵심은 두 가지 커스텀 포매터를 도입했습니다.
- BZConsoleJSONFormatter: Django 앱에서 발생하는 모든 로그를 JSON으로 변환
- GunicornJSONLogger: gunicorn의 액세스 로그와 에러 로그를 JSON으로 변환
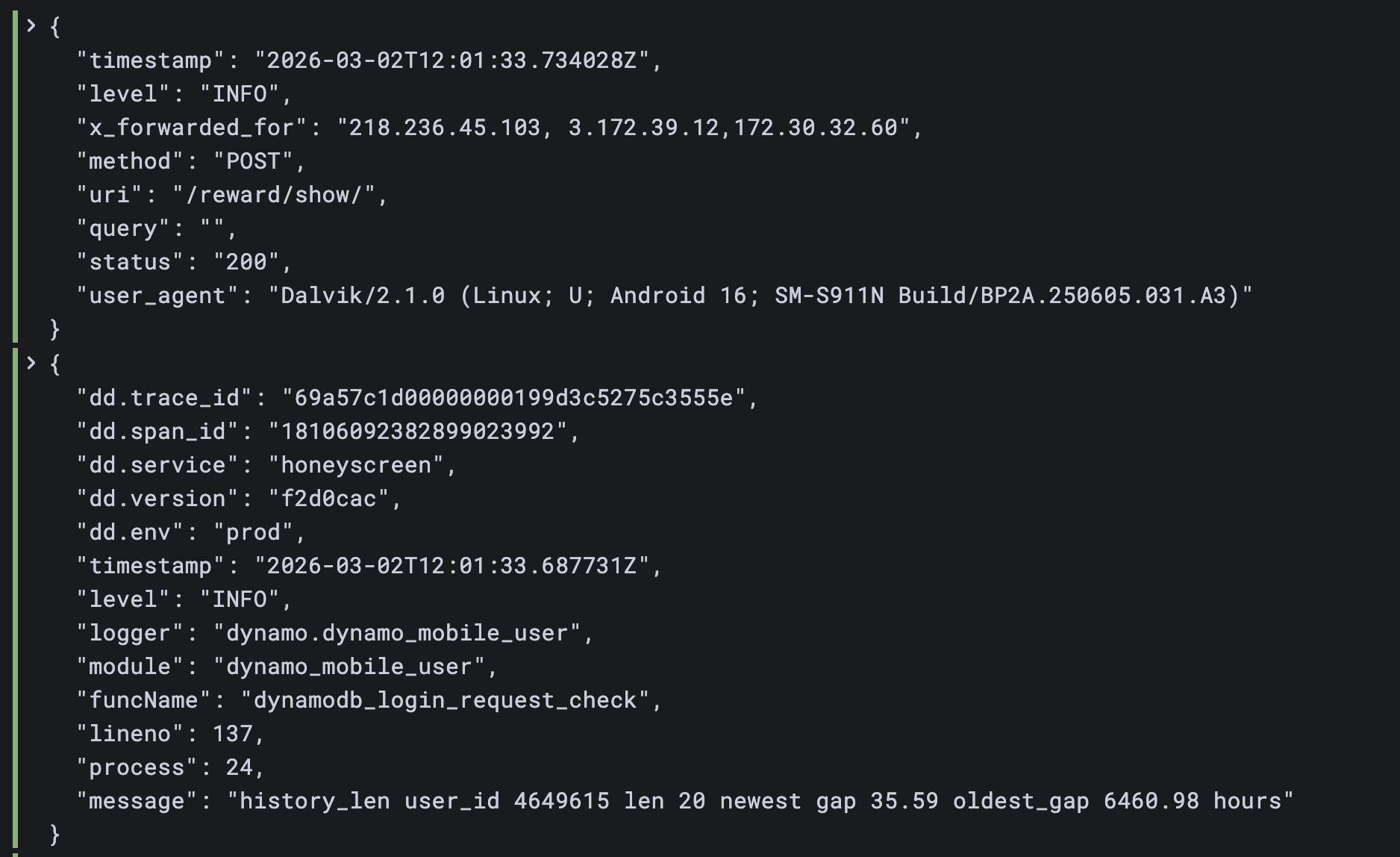
JSON으로 바꾸면 각 로그 이벤트가 하나의 JSON 객체로 출력되므로 Loki에서 필드 기반 쿼리가 가능해집니다. level이나 module 값으로 바로 필터링할 수 있고, 멀티라인 트레이스백도 하나의 JSON 필드 안에 들어가니 로그 이벤트 경계가 흐려지는 문제도 없어집니다.
settings.py 변경
Django의 로깅 설정에서 기존 verbose 포매터를 JSON 포매터로 교체했습니다.
python# Before - Django 기본 포매터 LOGGING = { 'formatters': { 'verbose': { 'format': '%(levelname)s %(asctime)s %(module)s %(message)s' }, }, 'handlers': { 'console': { 'class': 'logging.StreamHandler', 'formatter': 'verbose', }, }, } # After - JSON 구조화 포매터 LOGGING = { 'formatters': { 'json': { '()': 'common.bz_json_formatter.BZConsoleJSONFormatter', }, }, 'handlers': { 'console': { 'class': 'logging.StreamHandler', 'formatter': 'json', }, }, }
() 키를 사용하면 Django가 해당 클래스의 인스턴스를 직접 생성합니다. 기본 제공 포매터 대신 커스텀 포매터 클래스를 지정할 때 사용하는 방식입니다.
gunicorn 설정 변경
Django 앱 로그뿐 아니라 gunicorn 자체의 액세스/에러 로그도 JSON으로 통일해야 했습니다. gunicorn은 자체적인 로깅 시스템을 사용하기 때문에 별도로 logger_class를 지정해야 합니다.
python# Before accesslog = '-' errorlog = '-' # After logger_class = 'common.bz_json_formatter.GunicornJSONLogger' accesslog = '-' errorlog = '-'
accesslog과 errorlog의 - 값은 표준 출력(stdout/stderr)으로 로그를 내보내겠다는 의미로, 컨테이너 환경에서 로그를 수집하기 위한 표준적인 설정입니다. 여기에 logger_class만 추가하여 출력 형식을 JSON으로 바꿨습니다.
위 작업을 선행하여 마이그레이션 이후 에러가 발생했을 때 빠르게 원인 파악이 가능했습니다.
패키지 관리 현대화: pip-tools에서 uv로, flake8에서 ruff로
기존에는 pip-tools를 사용해 requirements.txt 파일을 관리하고 있었습니다. pip-compile로 라이브러리 디펜던시를 해석하고 pip-sync로 가상환경에 설치하는 방식이었죠.
pip 를 통한 패키지 매니징을 유지해도 됐지만 Python 버전업과 더불어 패키지 관리도 현대화하기로 했습니다.
uv는 Rust 기반이라 pip 대비 10~100배 빠른 의존성 해석 속도를 보여줍니다.
무엇보다 pip-compile + pip-sync 두 단계를 uv lock + uv sync 하나로 줄일 수 있다는 점이 마음에 들었습니다.
pyproject.toml 기반 표준 설정을 쓸 수 있고 크로스 플랫폼 lock 파일인 uv.lock 덕분에 로컬과 CI 환경 간 의존성 일치를 더 안정적으로 보장할 수 있었습니다.
toml# Before - requirements.txt (pip-tools) Django==2.2.28 djangorestframework==3.12.4 boto3==1.35.88 ... # After - pyproject.toml (uv) requires-python = ">=3.13" dependencies = [ "Django>=2.2.28,<3.0", "djangorestframework>=3.12.4", "boto3>=1.35.88", ]
코드 블록에서 보이듯 == 로 고정하던 버전 명시 방식이 >=로 바뀌었습니다. pyproject.toml에는 호환 가능한 범위만 명시하고 실제 설치 버전은 uv.lock이 결정하기 때문에 보안 패치나 버그 수정 같은 마이너 업데이트를 유연하게 반영할 수 있습니다.
uv 전환 시 겪은 이슈
전환 자체는 어렵지 않았지만 실제 CI와 배포 스크립트에 적용하면서 두 가지 이슈를 만났습니다.
virtualenv 활성화 문제
uv sync를 실행하면 프로젝트 루트에 .venv가 자동으로 생성됩니다. 문제는 기존 run.sh에서 python manage.py를 직접 호출하고 있었다는 점입니다. .venv를 활성화하지 않은 상태에서 python을 호출하면 시스템 Python이 실행되고 uv가 설치한 의존성을 찾지 못합니다.
bash# Before - 시스템 Python이 실행되어 ModuleNotFoundError 발생 python manage.py runserver # After - uv run으로 감싸서 .venv 컨텍스트에서 실행 uv run python manage.py runserver
uv run으로 감싸면 uv가 자동으로 .venv를 인식하고 올바른 Python 인터프리터를 사용합니다. 또는 run.sh 상단에서 명시적으로 source .venv/bin/activate를 호출하는 방법도 있습니다.
requires-python 엄격 검증
pip-tools 시절에는 requirements.txt에 Python 버전 제약이 없었기 때문에 Django 2.2와 Python 3.13의 호환성 문제가 설치 시점까지 드러나지 않았습니다. 하지만 uv는 pyproject.toml의 requires-python 선언을 기준으로 의존성 해석 단계에서 호환성을 검증합니다.
bash# requires-python = ">=3.13" 선언 후 uv lock 실행 시 error: No solution found when resolving dependencies: Because Django==2.2.28 requires Python <3.0 or >=3.4,<3.10 and your project requires Python >=3.13, Django==2.2.28 is incompatible
이 에러 덕분에 Django 2.2가 공식적으로 Python 3.9까지만 지원한다는 사실을 명확하게 확인할 수 있었습니다. pip-tools에서는 암묵적으로 넘어가던 비호환이 uv에서는 의존성 해석 단계에서 표면화되었습니다. 결과적으로 이 검증이 Python 버전업과 Django 버전업을 동시에 진행해야 하는 범위를 사전에 파악하는 데 도움이 되었습니다.
flake8에서 ruff로
Main 으로 사용하던 linter 도 flake8에서 ruff로 교체하며 속도 측면의 장점과 더불어 flake8-future-import, flake8-quotes 같은 플러그인들까지 ruff 하나로 대체할 수 있어서 도구 구성이 단순해졌습니다. ruff의 자동 수정 기능으로 50여개의 파일을 수정할 수 있었고 대부분 boolean 비교 수정(E712), 미사용 import 제거(F401), None 비교 수정(E711), printf-style의 f-string 전환(UP031) 등이 주된 수정이었습니다.
python# Before if status == True: import unused_module # F401 if value == None: result = "%s items" % count # After if status is True: # unused import removed if value is None: result = f"{count} items"
위는 ruff 도입 후 수정한 코드 중 하나로, 사소한 수정이지만 == 연산자는 객체의 __eq__를 호출하고 is는 동일성(identity)을 직접 비교합니다.
None이나 True/False 같은 싱글톤은 is로 비교하는 게 Python 관례이고 실제로 더 안전하다는 점도 배울 수 있었습니다.
프로덕션에서 마주친 에러들
prod 와 동일한 인프라를 공유하는 베타 서버에서 충분한 테스트를 거쳤음에도 배포 직후 다양한(?) 에러가 발생했습니다. 굉장히 다양한 에러가 발생해서 모두 공유드릴 순 없지만 python 2 -> 3 버전 업그레이드 과정에서 발생한 에러 위주로 정리했습니다. 다행히 큰 장애로 이어지진 않았기에 즉각적으로 처리했습니다.
base64.b64encode() 의 리턴 타입이 변경됨
base64.b64encode() 의 반환 타입이 달라지면서 DB에 저장된 암호화 데이터를 복호화하지 못해 InvalidCiphertextException 이 발생했습니다.
Python 2 공식 문서에서는 "Encode a string ... The encoded string is returned"로 명시하고 Python 3 에서는 "Encode the bytes-like object ... return the encoded bytes"로 변경된 것을 확인할 수 있습니다.
python# Python 2 base64.b64encode(data) # "SGVsbG8gV29ybGQ=" :str type # Python 3 base64.b64encode(data) # b"SGVsbG8gV29ybGQ=" : byte type
이 bytes 객체가 Django CharField에 저장되면 b'SGVsbG8gV29ybGQ='라는 문자열이 그대로 DB에 저장되는데 이후 복호화 시 base64.b64decode() 가 b' 접두사와 ' 접미사를 포함한 채 디코딩을 시도하면서 잘못된 바이너리가 만들어져 에러가 발생했습니다.
python# Before def encrypt(self, plaintext): response = client.encrypt(KeyId=KEY_ID, Plaintext=plaintext) return base64.b64encode(response["CiphertextBlob"]) # Python 3: bytes 반환! # After def encrypt(self, plaintext): response = client.encrypt(KeyId=KEY_ID, Plaintext=plaintext) return base64.b64encode(response["CiphertextBlob"]).decode('utf-8') # str로 변환
encrypt 쪽은 .decode('utf-8')을 붙여서 해결했지만 이미 b'...' 형태로 저장된 기존 데이터도 복호화할 수 있어야 했기 때문에 decrypt에는 접두사/접미사를 벗겨내는 보정 로직을 추가했습니다.
python# Before def decrypt(self, ciphertext): binary_data = base64.b64decode(ciphertext) response = client.decrypt(CiphertextBlob=binary_data) return response["Plaintext"] # After def decrypt(self, ciphertext): # Python 3 마이그레이션 이슈: bytes가 "b'...'" 문자열로 저장된 경우 보정 if isinstance(ciphertext, str) and ciphertext.startswith("b'") and ciphertext.endswith("'"): ciphertext = ciphertext[2:-1] binary_data = base64.b64decode(ciphertext) response = client.decrypt(CiphertextBlob=binary_data) return response["Plaintext"]
암호화/복호화처럼 바이너리를 다루는 코드는 Python 3의 str/bytes 구분이 엄격해진 만큼 마이그레이션 시 주의가 필요한 케이스였습니다.
None 과 Int 간 비교 금지
python 은 type assertion 이 강하지 않기 때문에 초기 개발 시 빠르게 개발할 수 있는 이점을 가지지만, 이러한 점이 되려 역효과를 내기도 합니다. 황당한 에러 중 하나였는데요 python2 코드는 아래처럼 비교 연산을 하고 있었습니다.
python# Before yob = yob if 1900 < yob < 2100 else None
이상한 점이 보이시나요? 전 보이지 않았습니다. 그래서 에러가 났나봐요.
yob 값이 None 인 사용자 요청이 들어와도 기존 python 2 에서는 문제없이 동작합니다.
python# Python 2 >>> 1900 < None < 2100 False # NoneType < int 알파벳 순서로 비교, 에러 없이 통과
Python 2의 CPython 구현에서는 서로 다른 타입을 비교할 때 타입 이름의 알파벳 순서로 비교하기 때문에 NoneType < int는 항상 True가 되고 결과적으로 else의 None으로 빠지면서 문제없이 코드가 진행됩니다.
Python 3에서는 공식 문서에 명시된 대로 의미 있는 자연 순서가 없는 피연산자 간 비교 연산(<, <=, >=, >)이 TypeError를 발생시킵니다.
python# Python 3 >>> 1900 < None < 2100 TypeError: '<' not supported between instances of 'int' and 'NoneType'
베타 서버에서는 테스트 유저에 year_of_birth가 전부 입력되어 있어서 이 에러를 발견할 수가 없었습니다. prod에서 None인 사용자가 로그인하는 순간에야 터지는 에러였습니다.
나눗셈 연산의 반환 타입 변경
Python 2에서 10 / 3은 3(int)이지만 Python 3에서는 3.3333(float)입니다. 연산 결과의 타입이 달라지면서 아래 코드에서도 에러가 발생했습니다.
python# Before count = total / step # Python 3: float 반환 if total % step != 0: count += 1 for i in range(count): # range()는 int만 받음!
range()는 정수만 받기 때문에 float 타입을 인자로 넘겨 에러가 발생했습니다. 아래처럼 정수 변환 후 인자로 넘기면 에러를 피할 수 있습니다.
python# After count = (total + step - 1) // step # 정수 ceiling division for i in range(count):
list comprehension 변수가 더 이상 새어나가지 않는다
이 케이스는 프로덕션이 아닌 ruff 린트에서 발견한 문제입니다. F821 undefined name 'refered_user_points' 에러가 잡혔는데, 쉽게 말하면 정의되지 않은 변수가 사용되었다는 의미입니다.
Python 2에서는 list comprehension의 루프 변수가 외부 스코프로 새어나가 comprehension이 끝나도 변수에 접근할 수 있습니다. 즉 명시적인 선언이 아닌 list comprehension 에서 선언된 temporal variable 이 외부에서도 사용된 셈이죠.
Python 3에서는 list comprehension이 자체 스코프를 가지기 때문에 바깥에서 접근하면 NameError 가 발생
python# Python 2 result = [x for x in range(5)] print(x) # 4 (루프 변수 누수!) # Python 3 result = [x for x in range(5)] print(x) # NameError: name 'x' is not defined
Python 2 환경의 flake8 린터에서는 변수 누수가 정상 동작이기 때문에 에러로 잡히지 않았습니다. CI도 Python 3로 전환해야 하는 이유 중 하나였습니다.
map()이 list 대신 iterator를 반환하다
어드민 페이지에서 설정 조회 시 500 에러가 발생했습니다.
Python 2의 map()은 list를 반환하지만 Python 3의 map()은 lazy iterator를 반환합니다. json.dumps()는 list는 직렬화할 수 있지만 iterator는 직렬화하지 못하기 때문에 에러가 발생했습니다.
python# Before configs = map( lambda config: config.to_dict(), self.config_set.all().select_related("config_rule"), ) return {"configs": configs} # map 객체가 그대로 포함 # After configs = list(map( lambda config: config.to_dict(), self.config_set.all().select_related("config_rule"), )) return {"configs": configs}
filter()나 zip()도 마찬가지로 Python 3에서는 lazy iterator를 반환하기 때문에 JSON 직렬화나 템플릿에 넘기는 곳에서는 list()로 감싸 반환하도록 수정했습니다.
마무리
긴 글이었는데요 레거시 파이썬 프로젝트를 모던 파이썬으로 마이그레이션한 과정을 정리하면 아래와 같습니다.
bash- Python 2.7 → 3.13 - Django 1.10.6 → 2.2.28 - numpy, pandas, redis, boto3, celery 등 60개 이상의 패키지 업데이트 - 171개 파일, +3,516/-1,489 lines
앞선 포스트에서는 CI 과정을 개선했고 이번 편에서는 로그 시스템 전환, 도구 교체(uv, ruff), 버전 마이그레이션, 프로덕션 에러 대응을 다뤘습니다. 사실 이번 작업은 팀에서 우선순위가 낮은 작업으로 꼭 python 버전업을 하지 않아도 비즈니스 문제를 해결하기엔 문제가 없었습니다. 다만 Claude Code 라는 강력한 도구 덕분에 본 업무 외에 사이드로 이번 작업을 진행할 수 있었습니다.
한가지 아쉬운 점이 있다면 Django 버전업을 더 진행하지 못한 부분입니다. 현재 최신 Django LTS는 5.2 버전으로 Django 3.0부터 render_to_response() 제거 및 force_text() → force_str() 전환 등 breaking change가 있어 djangorestframework를 비롯한 서드파티 라이브러리도 함께 올려야 했습니다. 현재 사용 중인 라이브러리 조합이 Django 2.2까지만 호환되는 상황이라 Python 버전업과 Django 버전업을 동시에 가져가기엔 변경 범위가 너무 커져 이번에는 Python 3 마이그레이션에 집중하고 Django 업그레이드는 다음 단계로 남겨두었습니다. 제 후임인 누군가가 잘 해줄거라 믿습니다.
10년도 더 된 python 2 서버를 python 3로 마이그레이션하는 대규모 작업이었지만, 저희 서비스를 사용하는 유저에게 표면적으로 달라진 부분은 없습니다. 비개발자 팀원 분들이 어떠한 체감도 못 느끼는 게 당연하고, 사실 개발자인 저도 크게 달라진 점은 모르겠습니다. 다만 더 이상 레거시를 두 손 놓고 놔두지 않아도 된다는 것, 또 다른 레거시 서버를 마이그레이션해야 할 때 훨씬 수월하게 진행할 수 있는 요령이 생긴 것은 분명한 성과입니다.
물론 이미 잘 돌아가고 있는 서버의 마이그레이션이 꼭 필요한가라는 생각도 들었습니다. 실제로 잘 돌아가던 크론잡에 에러가 생기면서 bm 팀의 작업에 차질을 빚기도 했지만 레거시 서버를 걷어내기 위해 필요한 대가였다고 생각합니다.